
Link
Introduction
좋은 코드의 기준은 언제나 명확하다. 작성하고 나서 1년 뒤에 읽어봐도 단번에 납득이 갈만한 코드가 그런데, 반대로 안 좋은 코드는 분명 작성한 사람이 나인데도 1달 정도 지나서 다시 보면 이해하는데 시간이 걸린다.
이는 적절한 등장인물과 쉽게 납득할만한 스토리의 묘사가 충분히 이루어지지 않았기 때문이라고 생각한다.
80%나 되는 개발자가 변수명을 짓는데에 어려움을 겪는다는 이유가 여기에 있다. 그 만큼 중요하니까. 이 코드 뭉치의 이야기를 전개해나가는 등장인물들이 명확하게 정의가 되어야 흐름이 눈에 보이니까.
최근에 더욱 이런 등장인물들의 행동 묘사와 이야기의 흐름에 대해 신경쓰며 코딩하고 있지만, 역시나 너무 어렵다. 이유는 두 가지 이다.
- 내가 생각해낸 단어를 보고 사람들은 다른 것을 연상할 수 있다. 소설의 경우는 이를 돕기 위해 지면을 들여 부연설명 및 묘사를 하는데, 코딩에 있어서는
늘어난 코드의 라인 = 복잡도이기 때문에 어떻게 해도 만족스럽지가 않다. 3+5와사과 3개가 있는데 거기에 사과 5개를 더한다는 설명은 결과물은 같을 수 있어도 그 안의 상황은 완전 다르다. 컴퓨터가 필요로 하는게3+5라면 내가 작성한 코드를 읽는 사람들에게 더 도움이 되는 표현방법은사과 3개가 있는데 거기에 사과 5개를 더한다고 하는 상상 속 세계 안에서 벌어지고 있는 어떤 사건들이다. 이 절충점을 잡는 것이 너무나도 어렵다.
이번 문제를 풀면서도 이걸 어떻게 더 읽기 쉽게 만들 수 있을까 하는 고민을 엄청 많이 했지만 작성해 놓고 다시 보니 아직 한참 멀은 것 같다.
Note
- 유일성과 최소성을 체크할 방법을 생각한다.
Solution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from itertools import combinations
from collections import defaultdict
def check_minimality(index_set, registered_index_sets):
for registered_index_set in registered_index_sets:
if (index_set & registered_index_set) == registered_index_set:
return False
return True
def get_unique_column_index_sets(relation, columns, no_of_cols):
index_dict = defaultdict(set)
for index_comb in combinations(columns, no_of_cols):
for tuple_ in relation:
value_comb = tuple([tuple_[index] for index in index_comb])
index_dict[index_comb].add(value_comb)
return [set(indexes) for indexes, values in index_dict.items() if len(values) == len(relation)]
def solution(relation):
registered_index_sets = []
columns = [i for i in range(len(relation[0]))]
for no_of_cols in range(1, len(columns)+1):
index_sets = get_unique_column_index_sets(relation, columns, no_of_cols)
for index_set in index_sets:
is_valid = check_minimality(index_set, registered_index_sets)
if is_valid:
registered_index_sets.append(index_set)
return len(registered_index_sets)
1. 필요한 함수 정의
이 문제의 핵심 키워드는 두 가지이다. 바로 유일성(uniqueness)과 최소성(minimality). 이를 판별해 줄 수 있는 함수를 정의해보자.
유일성부터 살펴보자면, 우선 우리에겐 (이름, 전공)과 같은 유니크한 조합을 반환하는 함수가 필요하다.
튜플의 정보를 모두 사용하기에는 너무 용량이 크니까 인덱스만 다루는 걸로 하고 원본 릴레이션, 컬럼 인덱스 리스트, 그리고 조합할 컬럼 갯수를 넣어주면 유니크한 컬럼 인덱스 조합셋을 반환하는 함수를 만든다고 하자.
1
2
3
4
5
6
def get_unique_column_index_sets(relation, columns, no_of_cols): # 1-1
pass
def solution(relation):
answer = []
return answer
다음은 최소성인데, 이런 경우를 생각해볼 수 있다.
유일성만 따졌을 때 (이름, 전공)과 (이름, 전공, 학년) 조합은 똑같이 유일한 조합이지만, 이미 (이름, 전공)이 정답리스트에 포함되어 있다면 (이름, 전공, 학년)을 고려할 필요가 없다.
따라서 이 경우를 체크하는 함수를 정의해준다. 필요한 것은 체크할 인덱스 조합셋과, 이미 등록되어 있는 인덱스 조합셋 리스트이다.
1
2
3
4
5
6
7
8
9
def check_minimality(index_set, registered_index_sets): # 1-2
pass
def get_unique_column_index_sets(relation, columns, no_of_cols):
pass
def solution(relation):
answer = []
return answer
2. 주어진 함수 사용
우선 유효한 인덱스 조합셋을 저장할 리스트와 컬럼 인덱스 리스트를 생성한다.
1
2
3
def solution(relation):
registered_index_sets = []
columns = [i for i in range(len(relation[0]))]
그 후에 조합할 컬럼 갯수 1개부터 모든 컬럼의 갯수까지 순회하며 아래의 과정을 거쳐 릴레이션을 체크한다.
- 컬럼 갯수별로 유니크한 컬럼 인덱스 조합 리스트를 생성한다.
- 이 컬럼 인덱스 조합들의 최소성을 체크하고 유효하면 정답에 넣는다.
1
2
3
4
5
6
7
8
9
10
def solution(relation):
registered_index_sets = []
columns = [i for i in range(len(relation[0]))]
for no_of_cols in range(1, len(columns)+1):
index_sets = get_unique_column_index_sets(relation, columns, no_of_cols) # 2-1
for index_set in index_sets:
is_valid = check_minimality(index_set, registered_index_sets) # 2-2
if is_valid:
registered_index_sets.append(index_set)
return len(registered_index_sets)
3. 함수 구현 - 유니크 인덱스 셋
유니크 인덱스를 만들기 위해 이런 형태의 dictionary를 만드려고 한다.
1
2
3
4
5
6
7
8
9
10
{
"(0, 1)": [
[100, "ryan"],
[200, "apeach"]
],
"(2, 3)": [
["music", 2],
["math", 2]
]
}
key는 인덱스의 조합, value는 튜플의 해당 인덱스의 value 조합이다.
우선 default value를 set으로 가지는 defaultdict를 만들어준다
1
2
3
4
from collections import defaultdict
def get_unique_column_index_sets(relation, columns, no_of_cols):
index_dict = defaultdict(set) # 3-1
파이썬의 내장 라이브러리 combinations(iterable, r)는 배열과 갯수를 집어넣으면 조합을 만들어 반환한다. 이를 이용해 모든 인덱스 조합을 만든다.
1
ex) combinations([1, 2, 3, 4, 5], 2) = [(1, 2), (1, 3), ...]
1
2
3
4
5
6
7
from itertools import combinations
from collections import defaultdict
def get_unique_column_index_sets(relation, columns, no_of_cols):
index_dict = defaultdict(set)
for index_comb in combinations(columns, no_of_cols): # 3-2
pass
인덱스 조합별로 릴레이션의 튜플의 인덱스에 해당하는 값을 꺼내 index_dict에 넣는다.
파이썬에서 hashable한 것은 tuple(()) 뿐이므로 list([]) 형태로 바로 넣어주지 않고 tuple() 생성자를 통해 list를 tuple로 바꿔서 넣어준다.
1
2
3
4
5
6
7
8
9
from itertools import combinations
from collections import defaultdict
def get_unique_column_index_sets(relation, columns, no_of_cols):
index_dict = defaultdict(set)
for index_comb in combinations(columns, no_of_cols):
for tuple_ in relation:
value_comb = tuple([tuple_[index] for index in index_comb]) # 3-3
index_dict[index_comb].add(value_comb) # 3-3
index_dict에 들어 있는 value set 중 원래 릴레이션의 튜플의 갯수와 같은 인덱스 조합이 있다면 이를 set의 형태로 리스트를 만들어 반환한다.
1
2
3
4
5
6
7
8
9
10
from itertools import combinations
from collections import defaultdict
def get_unique_column_index_sets(relation, columns, no_of_cols):
index_dict = defaultdict(set)
for index_comb in combinations(columns, no_of_cols):
for tuple_ in relation:
value_comb = tuple([tuple_[index] for index in index_comb])
index_dict[index_comb].add(value_comb)
return [set(indexes) for indexes, values in index_dict.items() if len(values) == len(relation)] # 3-4
4. 함수 구현 - 최소성 체크
파라미터로 받은 index_set과 registered_index_set의 교집합이 registered_index_set과 같다면 index_set은 이미 index_set은 이미 체크가 된 것이다.
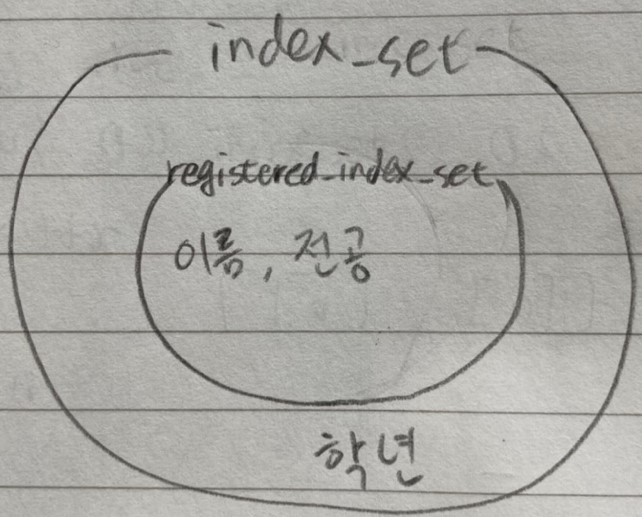 index_set이 registered_index_set보다 덩치가 큰 경우
index_set이 registered_index_set보다 덩치가 큰 경우
1
2
3
4
5
def check_minimality(index_set, registered_index_sets):
for registered_index_set in registered_index_sets: # 4-1
if (index_set & registered_index_set) == registered_index_set:
return False
return True
Comment
하루 만에 안 풀려서 진짜 몇 일에 걸쳐서 고민했던 문제였다
다른거 하다가 생각나면 다시 풀어보고 안 되면 잠깐 냅두고 또 다른거 하고..코딩테스트에서 풀었다면 아마 난 이 문제를 바로 틀렸겠지
뭔가 아이디어는 떠오르는데 구현이 잘 안 되었던 문제였던 것 같고, 풀이도 가독성이 그렇게 좋아보이지는 않아서 너무 아쉽다. 추후에 리팩토링을 하던 다른 아이디어로 풀어보던지 해야할 것 같다.